项目演示视频
是否包含论文文档
是
详细描述
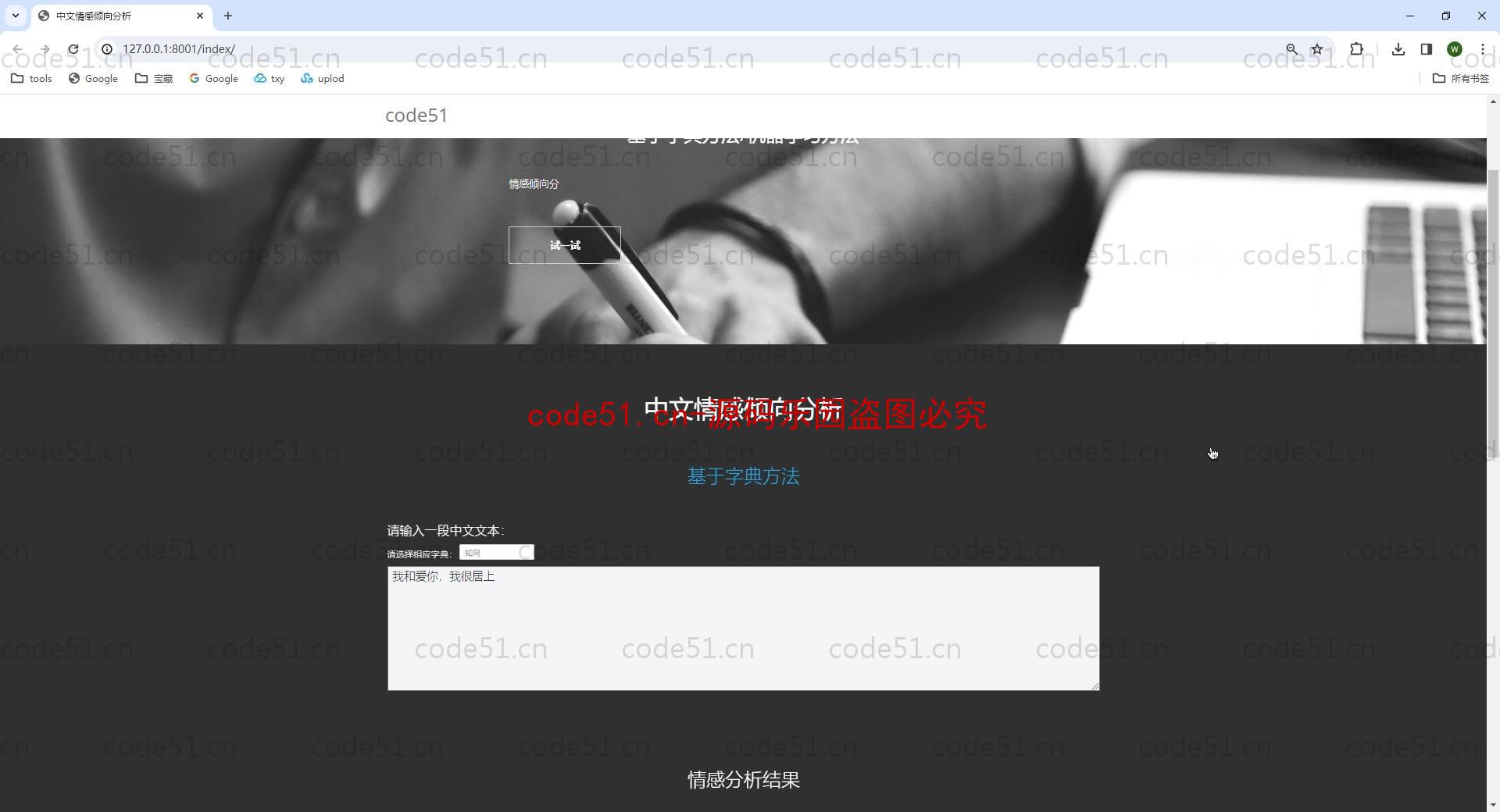
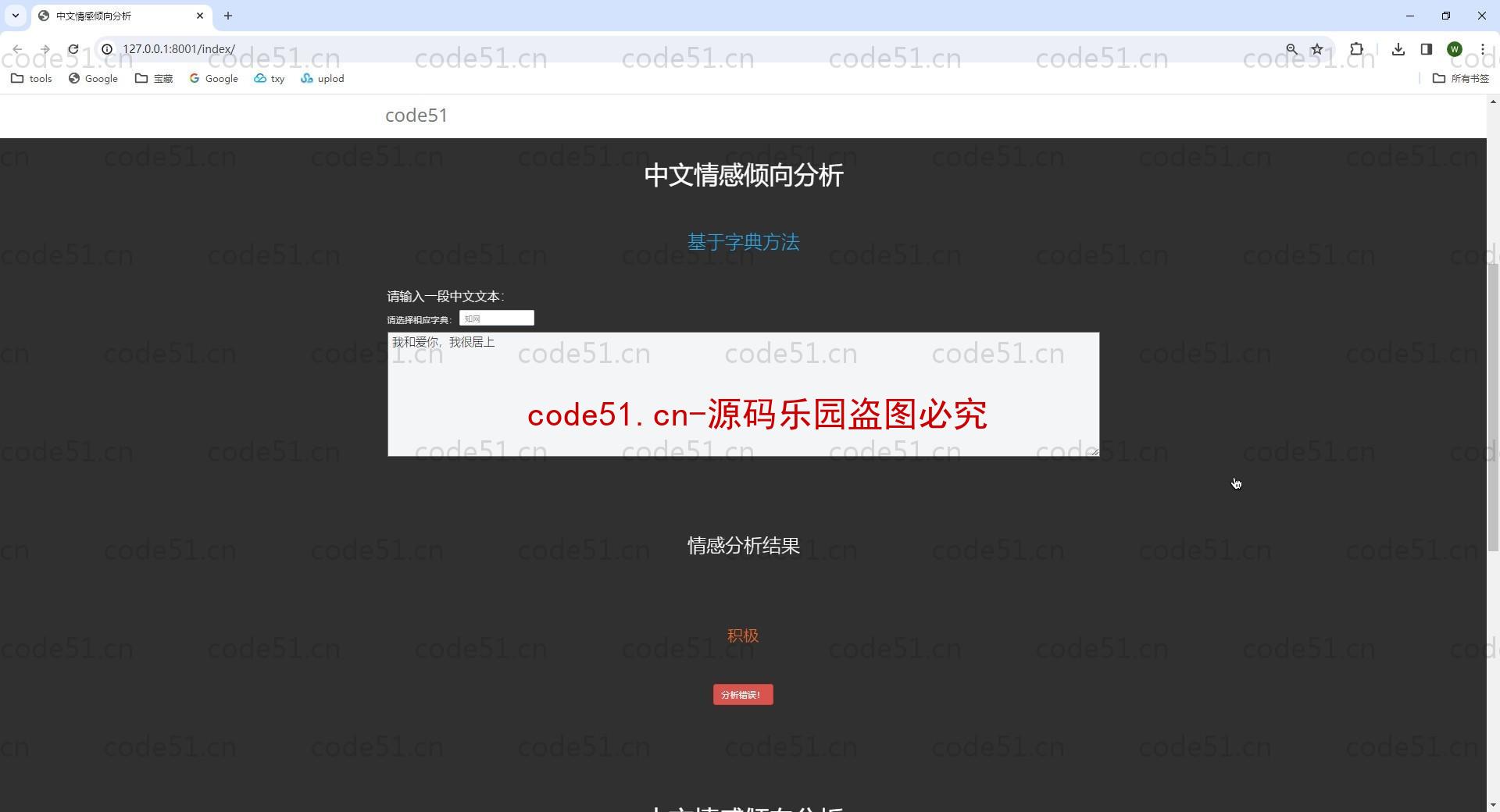
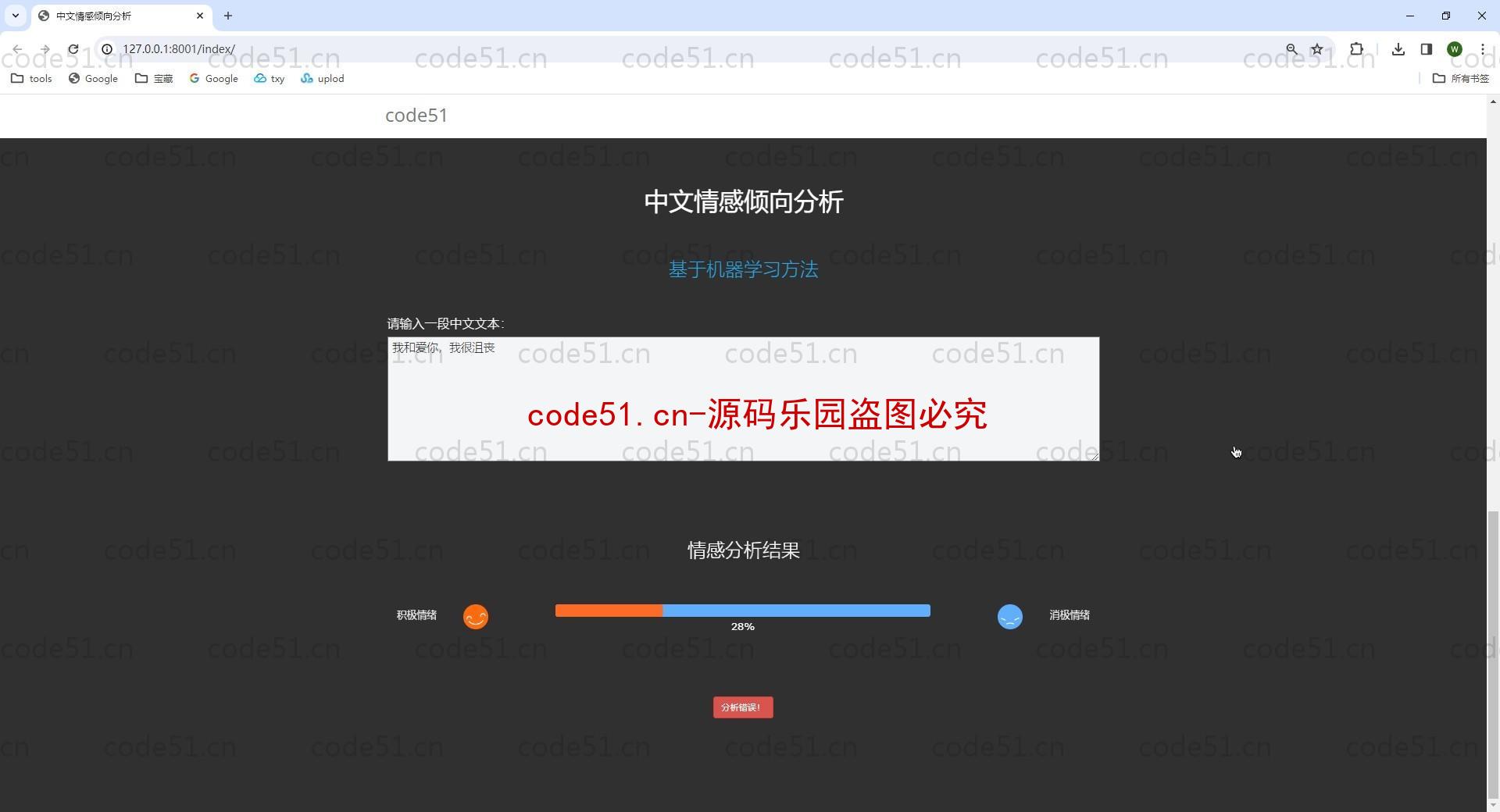
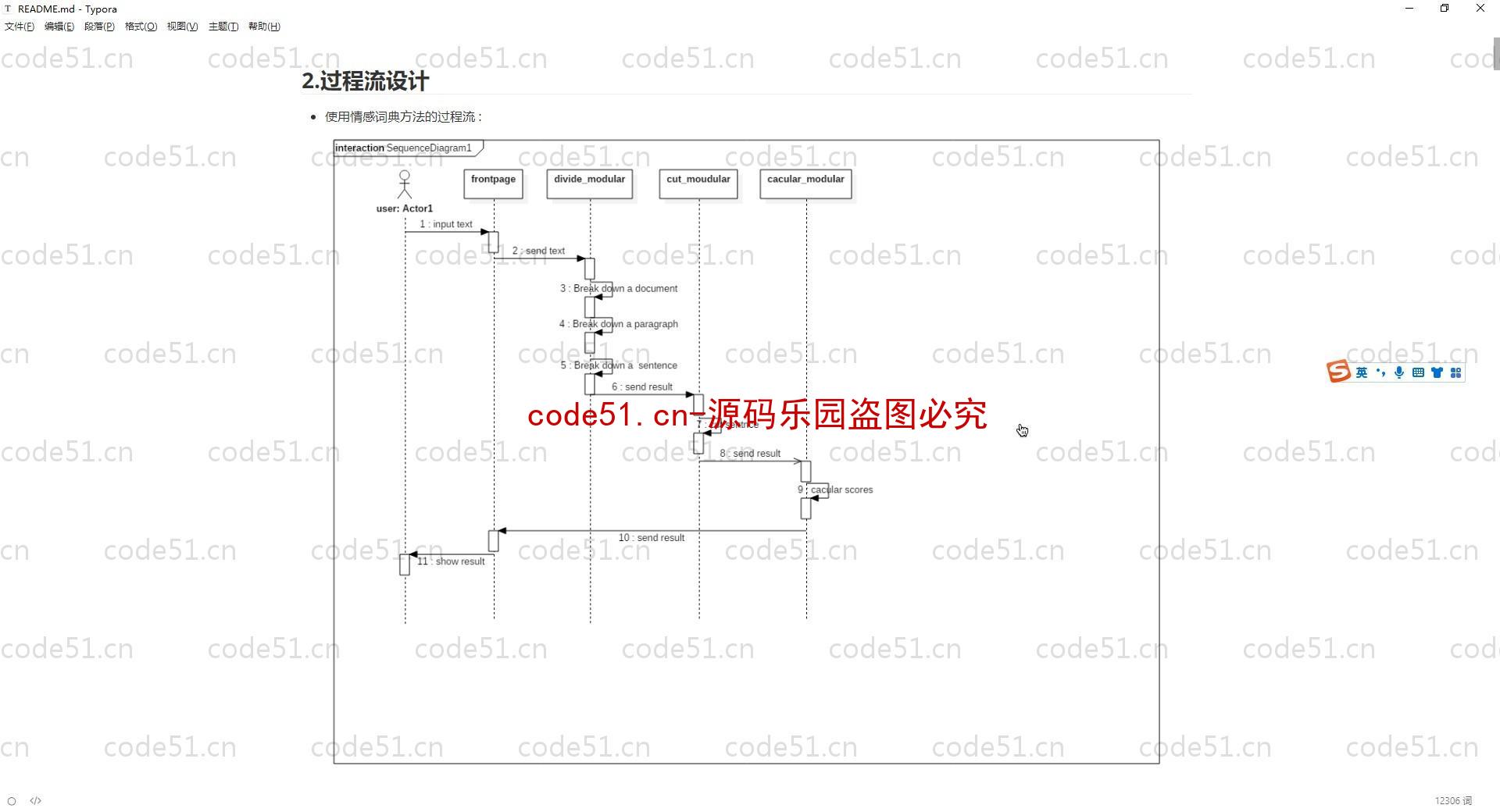
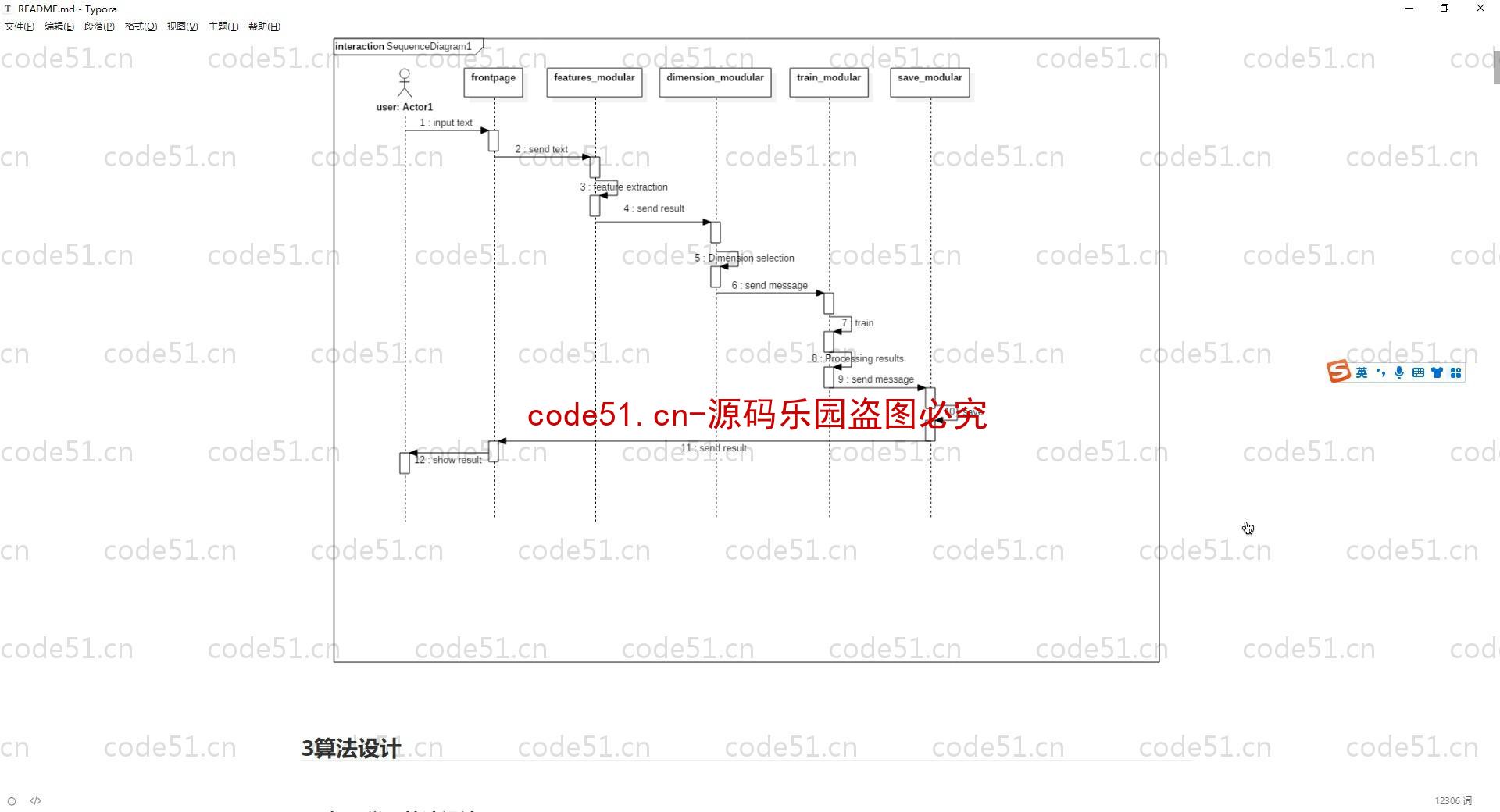
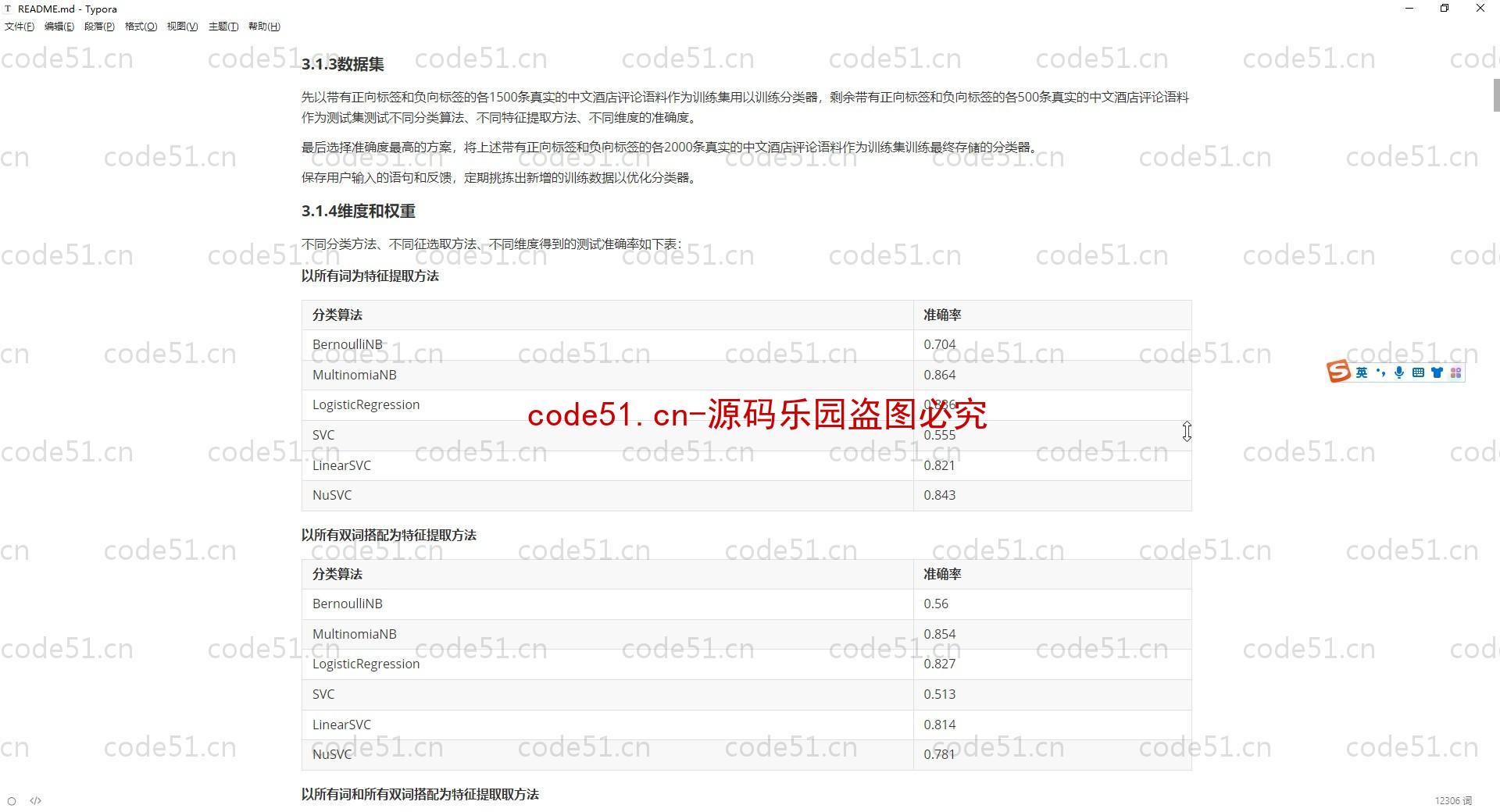
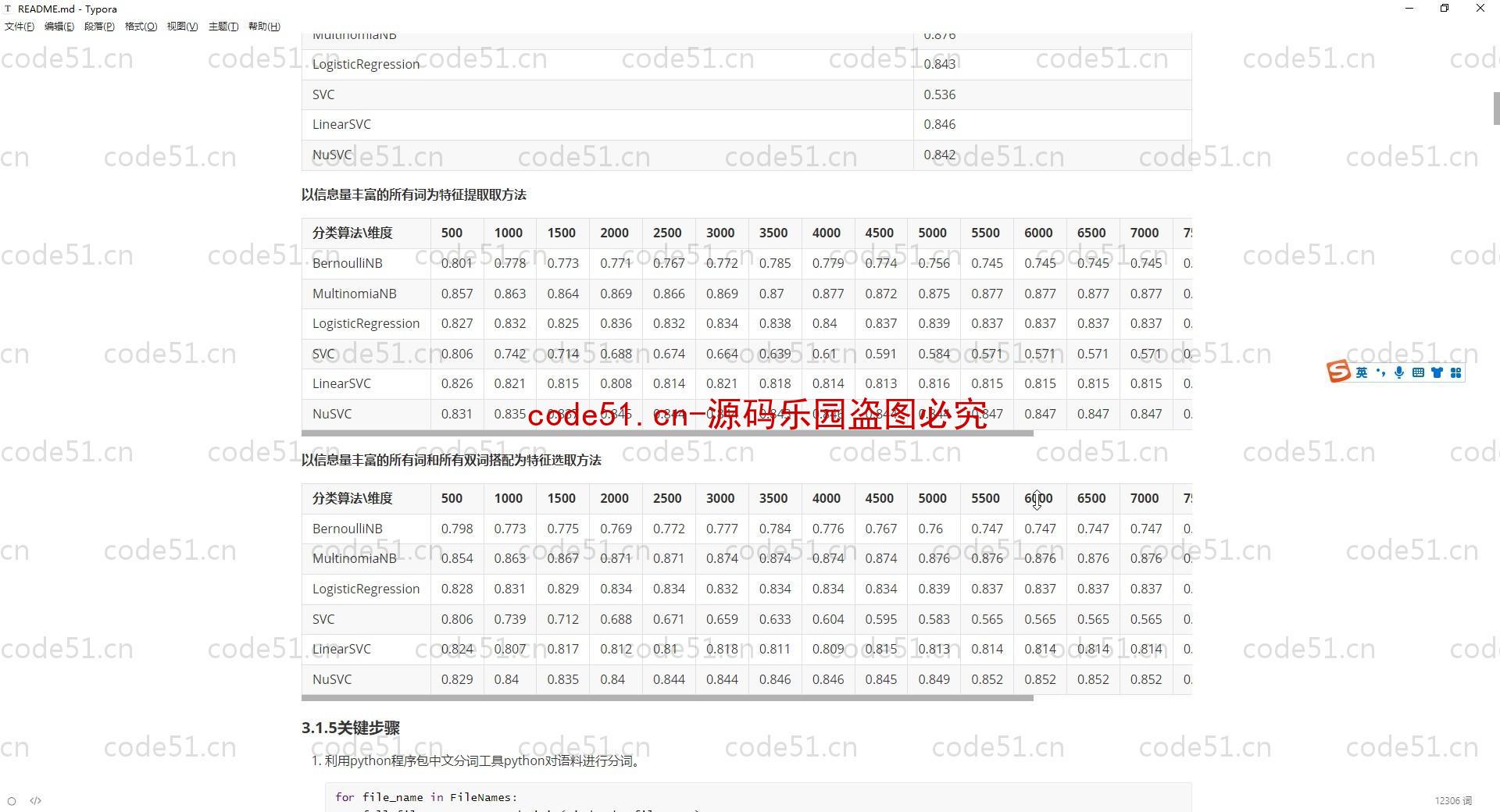
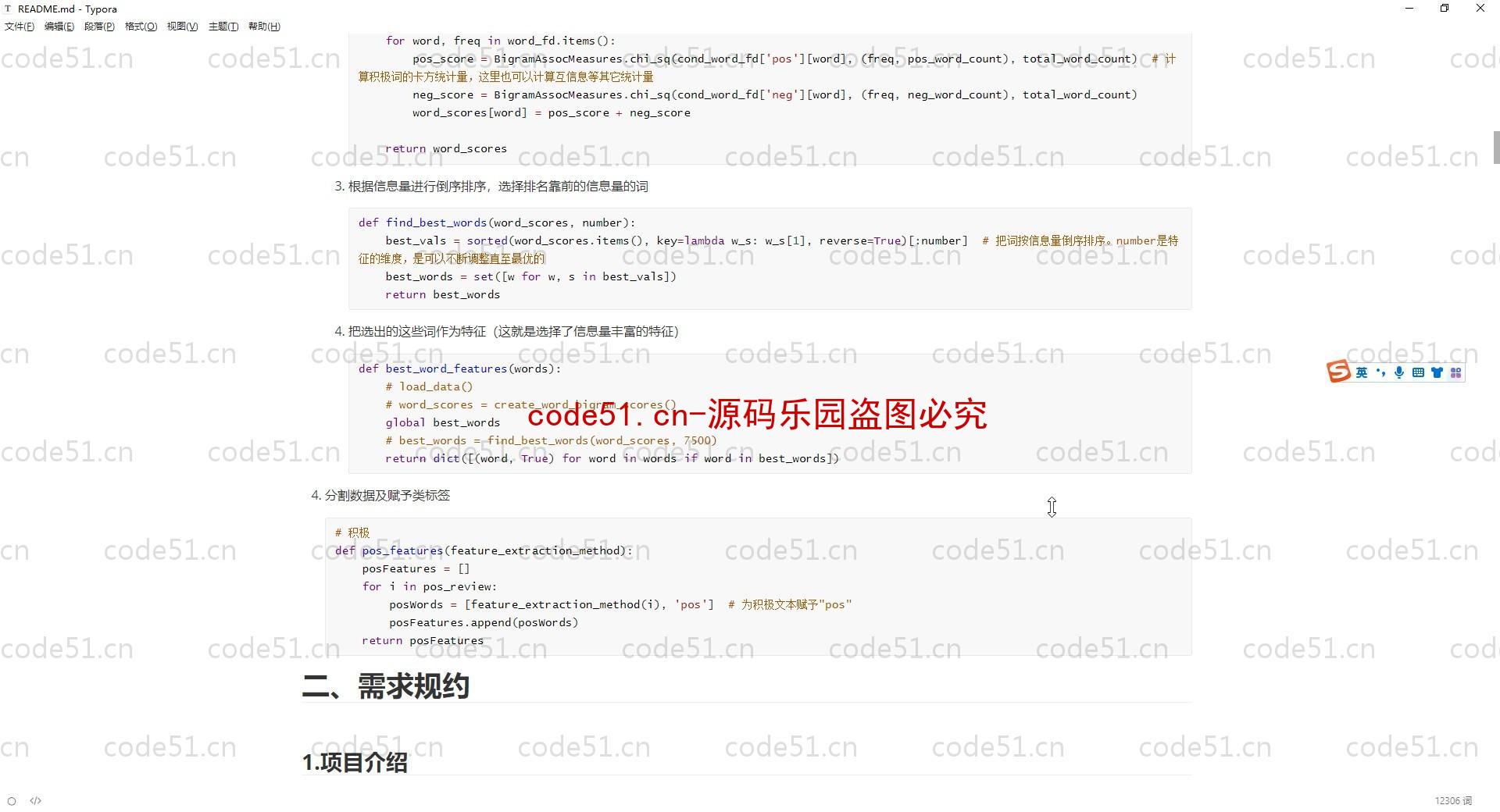
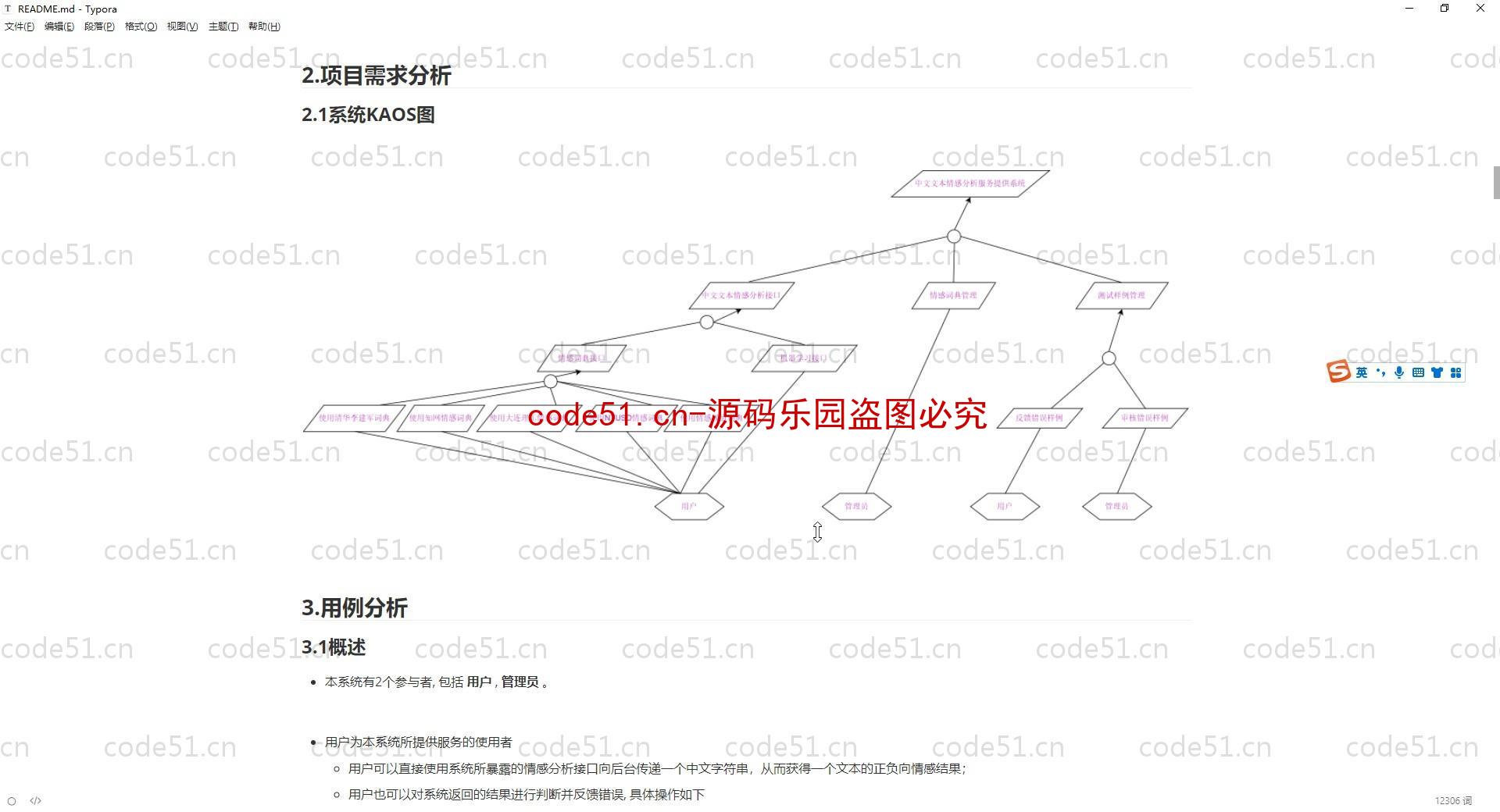
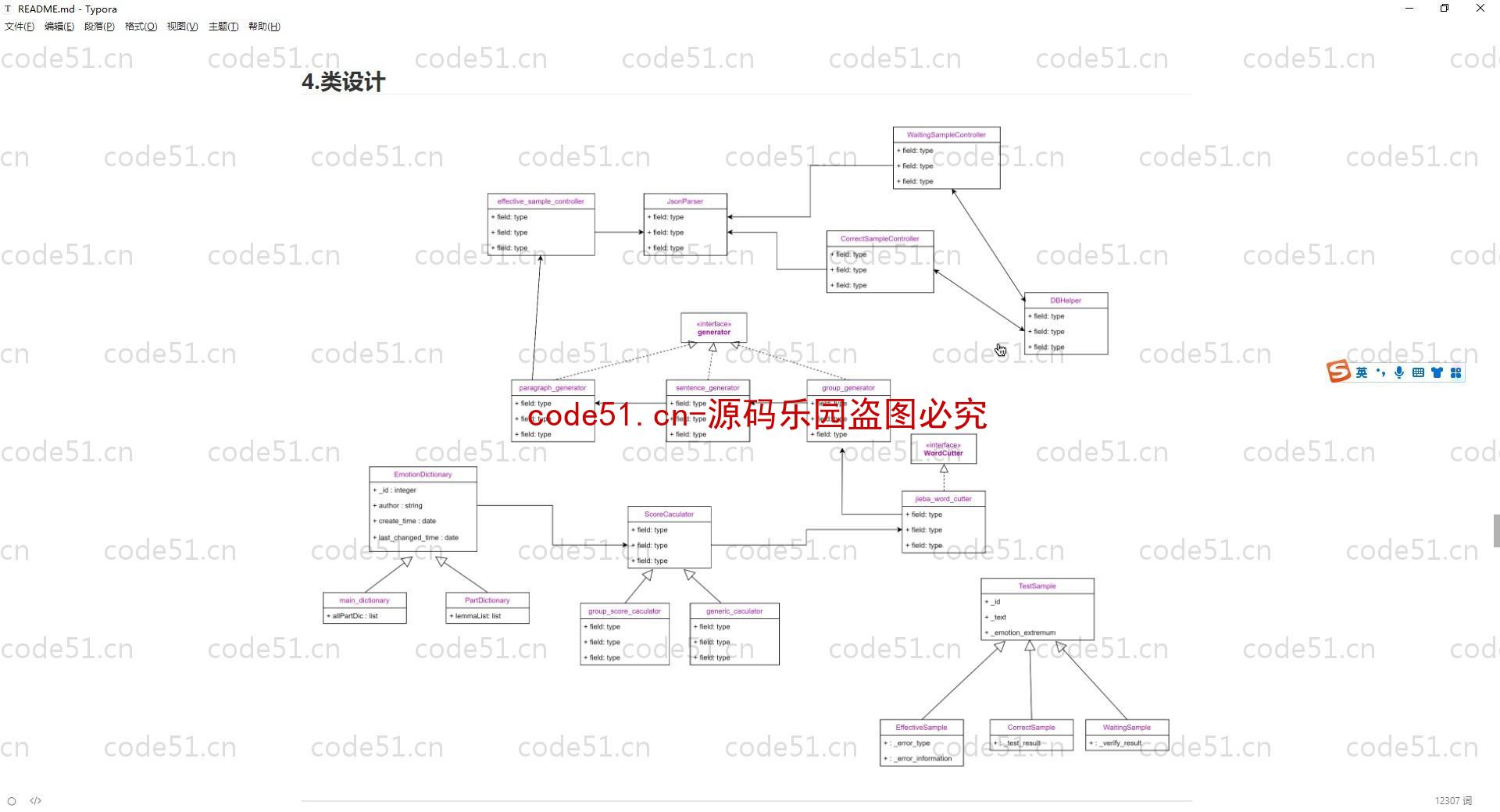
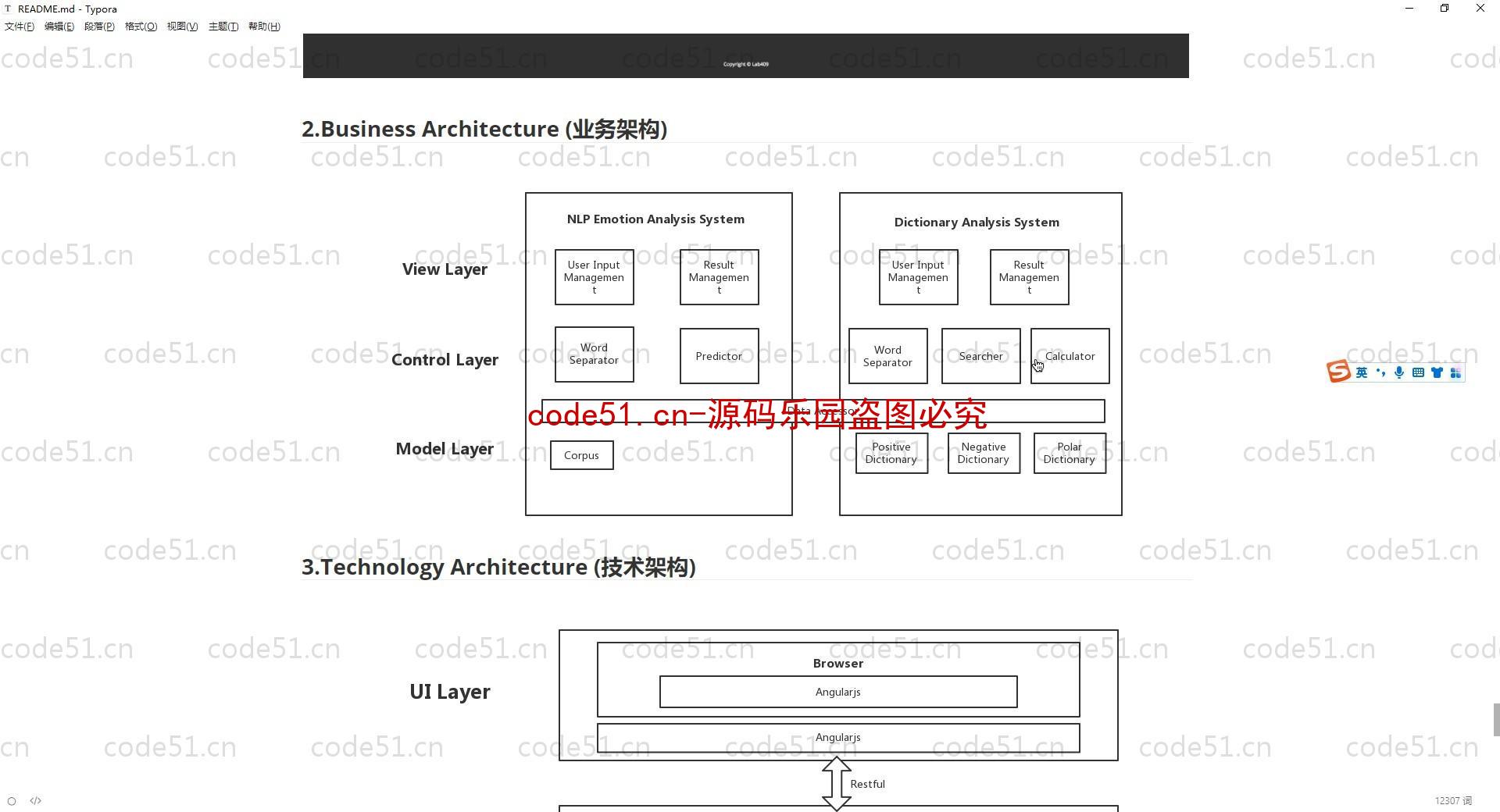
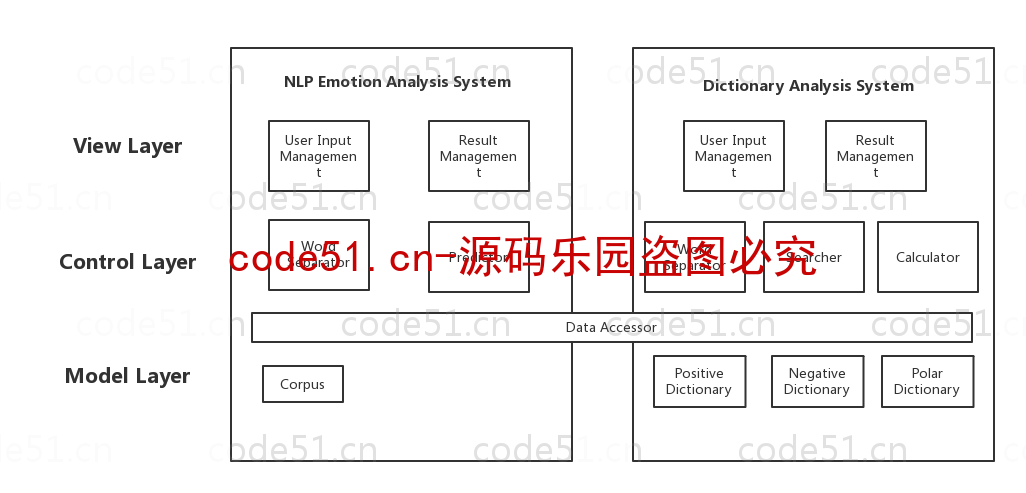
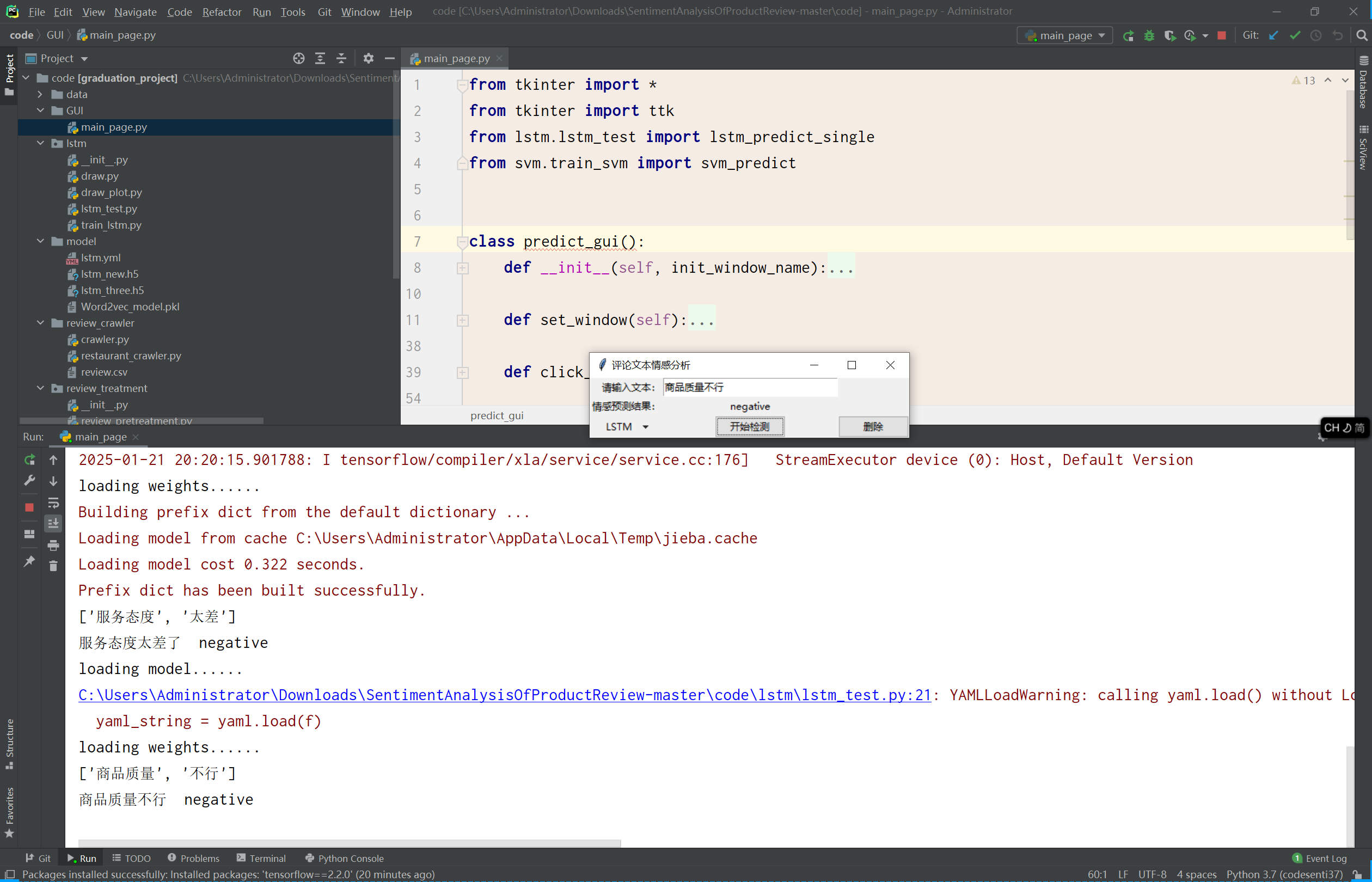
基于Python+Django+机器学习+情感词典的文本情感分析系统(附文档),情感倾向分析的方法主要分为两类:一种是基于情感词典的方法;一种是基于机器学习的方法,如基于大规模语料库的机器学习。前者需要用到标注好的情感词典,英文的词典有很多,中文主要有知网整理的情感词典Hownet和台湾大学整理发布的NTUSD两个情感词典,还有哈工大信息检索研究室开源的《同义词词林》可以用于情感词典的扩充。基于机器学习的方法则需要大量的人工标注的语料作为训练集,通过提取文本特征,构建分类器来实现情感的分类。文本情感分析的分析粒度可以是词语、句子也可以是段落或篇章。段落篇章级情感分析主要是针对某个主题或事件进行倾向性判断,一般需要构建对应事件的情感词典,如电影评论的分析,需要构建电影行业自己的情感词典效果会比通用情感词典效果更好;也可以通过人工标注大量电影评论来构建分类器。句子级的情感分析大多事通过计算句子里包含的所有情感词的平均值来得到。篇章级的情感分析,也可以通过聚合篇章中所有的句子的情感倾向来计算得出。因此,针对句子级的情感倾向分析,既能解决较短文本的情感分析,同时也可以是篇章级文本情感分析的基础。
技术描述
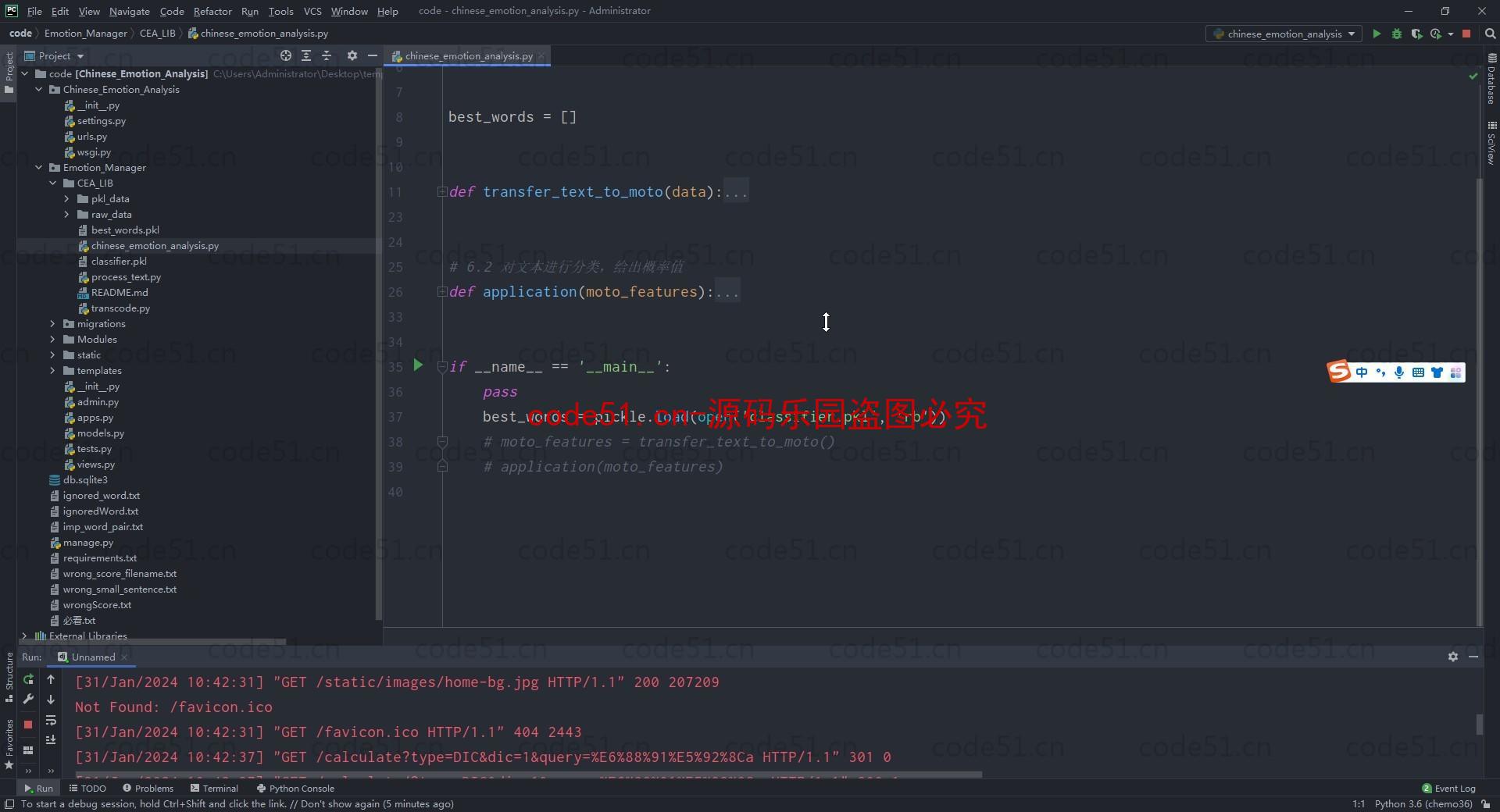
开发工具: Pycharm
数据库: MySQL
Python版本:3.8.x
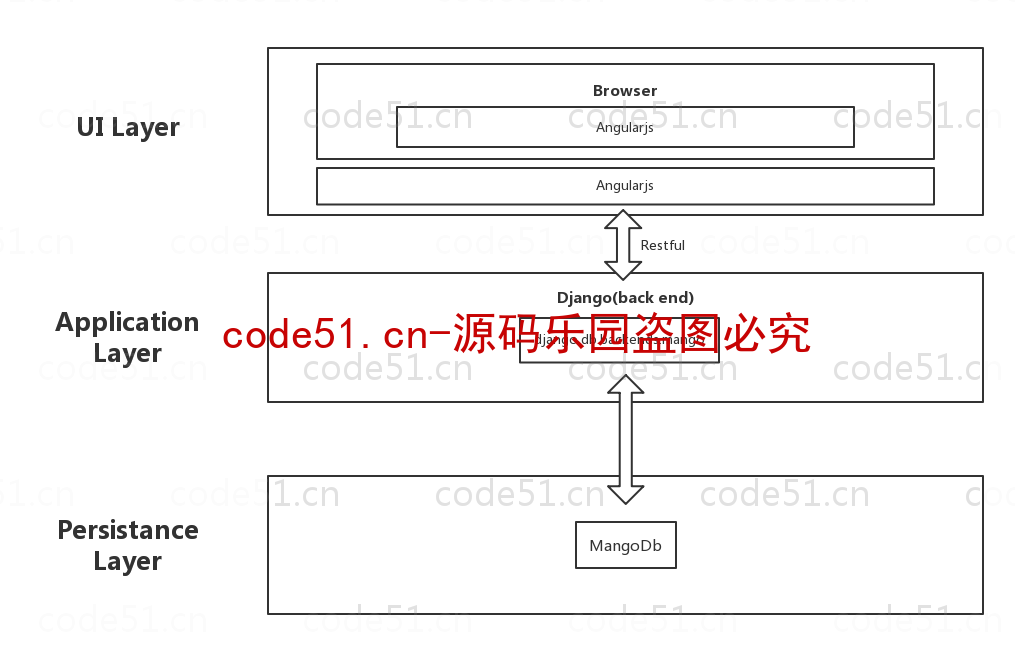
后端框架: Python/Django/机器学习/算法
项目截图描述
部分截图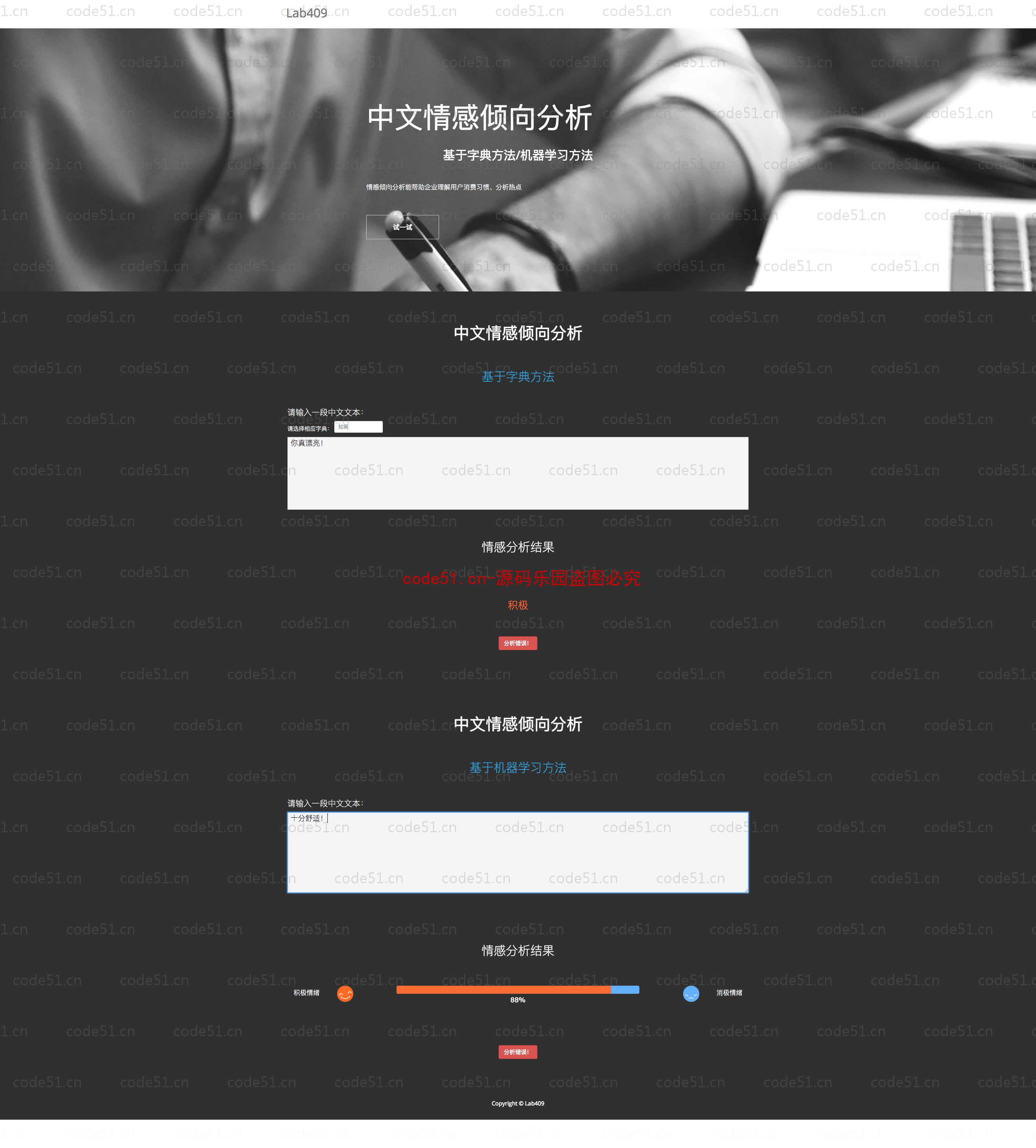
部分截图